Oracle Interview Questions
1. SQL query to return employee record with highest salary
2. SQL query to return highest salary from employee table
3. SQL query to return second highest salary from employee table
4. SQL query to return range of employees based on ID
5. SQL query to return employee name, highest salary and department name
6. SQL query to return highest salary, employee name, department name for each department
7. Difference between TRUNCATE and DELETE
8. Difference between Procedure and Function
9. NVL, NVL2, NULLIF, COALESCE
10. Difference between RANK and DENSE RANK
11. Types of SQL commands
12. How to get unique records without using DISTINCT keyword
13. What is DUAL table
14. What is Trigger and types of triggers
15. Difference between DECODE and CASE
16. Difference between TRANSLATE and REPLACE
17. Views, Simple View and Complex View
18. Difference between View and Materialized View
19. Pseudo columns, Aggregate or Group functions, Analytic functions
20. Features of Oracle 12.2
20.1 Object name greater than 30 characters
20.2 Utilizing LISTAGG function for string greater than 4000 characters
20.3 Session sequence
20.4 DDL Logging
20.5 JSON functions
21. SQL query to return nth highest record or <nth records
22. Index
23. EXISTS
24. DML error logging tables
25. NOCOPY Hint
26. Exclude duplicate records while insertion
27. Interface types
i) SQL *Loader
ii) UTL_FILE package
iii) External Table
iv) iSetup
v) Data Loader
vi) Web ADI
28. Difference between VARCHAR and VARCHAR2
29. Difference between WHERE and HAVING
30. EBS Cycles
31. Conversion or Interfaces
32. Analyze
33. MERGE
34. Difference between COUNT(*), COUNT(expr), COUNT(DISTINCT expr)
35. REF Cursor
36. SYS REF Cursor
37. PRAGMA AUTONOMOUS_TRANSACTION
38. Difference between 11i and R12
39. Difference between R12.1.3 and R12.2
40. TCA
1. SQL query to return employee record with highest salary
SELECT * FROM emp WHERE sal = (SELECT MAX(sal) FROM emp);
2. SQL query to return highest salary from employee table
SELECT MAX(sal) FROM emp;
3. SQL query to return second highest salary from employee table
SELECT MAX(sal) FROM emp WHERE sal NOT IN (SELECT MAX(sal) FROM emp);
4. SQL query to return range of employees based on ID
SELECT * FROM emp WHERE emp_id BETWEEN 1000 AND 2000;
5. SQL query to return employee name, highest salary and department name
SELECT e.emp_name, e.sal, d.dept_name FROM emp e, dept d WHERE e.deptno = d.deptno AND e.sal IN (SELECT MAX(sal) FROM emp);
6. SQL query to return highest salary, employee name, department name for each department
SELECT e.emp_name, e.sal, d.dept_name FROM emp e, dept d WHERE e.deptno = d.deptno AND e.sal IN ( SELECT MAX(sal) FROM emp GROUP BY deptno);
7. Difference between TRUNCATE and DELETE
| TRUNCATE | DELETE |
| DDL command (CREATE, ALTER, DROP, TRUNCATE) | DML command (INSERT, UPDATE, DELETE) |
| All records will be deleted. No WHERE clause | Selective records can be deleted using WHERE clause |
| Resets the high level watermark in DB | Does not resets the high level watermark in DB |
| Implicitly (indirectly/ unintentionally) executes auto COMMIT and cannot be rollbacked | This required explicit COMMIT and we can ROLLBACK the records before COMMIT |
| Releases all locks associated to that session, clearing the SAVEPOINT’s | The corresponding records are locked to other users and the deleted records are placed into the ROLLBACK segment area |
DB triggers will not fire when TRUNCATE statement is executed
|
DB triggers will fire when DELETE statement is executed |
| Faster | Slower because it uses undo segment |
| Retrieve the space used by table
SELECT bytes FROM dba_segments WHERE segment_name = ‘EMP_SAMPLE’; |
Will not retrieve the space used by table |
| When trying to delete parent table records even the child table records will be deleted by using ‘TRUNCATE TABLE <tab_name> CASCADE’ from Oracle 12C. The table should be created using ‘ON DELETE CASCADE’ key word | When trying to delete parent table records even the child table records will be deleted by using ‘ON DELETE CASCADE’ from Oracle 12C. The table should be created using ‘ON DELETE CASCADE’ key word |
8. Difference between Procedure and Function
| Procedure | Function |
| Procedure may return or may not return a value | Function has to return a single value and should have RETURN clause in its definition. |
| It may return one or more values using OUT & INOUT parameters | |
| Procedure can be called only in PL/SQL block | Function can be called in SELECT statements |
| Procedure can have IN, OUT, INOUT parameters | Function can have IN, OUT and INOUT parameters. However in real time we use only IN parameter. Just in case we have OUT and INOUT parameter then that function cannot be executed using SELECT statement.1. The below code executes and it has only IN parameter 2. Function with IN & OUT parameter |
| RETURN keyword exits the procedure | RETURN keyword returns the value. Function can be compiled without RETURN keyword but SELECT query will not be executed. |
| IN – Read only; OUT – Write only; IN OUT – Read/ write; |
|
| DDL and DML statements can be used directly | DDL and DML statements can be used using PRAGMA AUTONOMOUS_TRANSACTION
1. The below code executes 2. The below DML code errors 3. The below DML code executes 4. The below DDL code executes 5. The below DML code executes when executing in PL/SQL block as an expression 6. The below DML code errors when executing in PL/SQL block in SELECT statement |
9. NVL, NVL2, NULLIF, COALESCE
SELECT NVL('A', 'B') result FROM DUAL; /*If first value ('A') is NULL then returns second value ('B') else returns first value ('A')*/
SELECT NVL(NULL, 'B') result FROM DUAL; /*Here first value is NULL so returns second value*/
SELECT NVL('A', NULL) result FROM DUAL; /*Here first value is NOT NULL so returns first value*/
SELECT NVL(NULL, NULL) result FROM DUAL; /*Here both are NULL so returns NULL value*/
SELECT NVL2('A', 'B', 'C') result FROM DUAL; /*If first value ('A') is NOT NULL then returns second value ('B') else returns third value ('C')*/
SELECT NVL2(NULL, 'B', 'C') result FROM DUAL; /*Here first value is NULL so returns third value ('C')*/
SELECT NVL2('A', NULL, 'C') result FROM DUAL; /*Here first value is NOT NULL so returns second value (NULL)*/
SELECT NULLIF('A', 'A') result FROM DUAL; /*If both are same then returns NULL*/
SELECT NULLIF('B', 'C') result FROM DUAL; /*If both are not same then returns first value ('B')*/
SELECT NULLIF(NULL, 'C') result FROM DUAL; /*If first value is NULL then we get error*/
SELECT NULLIF('A', NULL) result FROM DUAL; /*Here first value is NOT NULL so we get first value ('A')*/
SELECT COALESCE('A', 'B', 'C', 'D', 'E') result FROM DUAL; /*Can have n number of values and returns first NOT NULL value ('A')*/
SELECT COALESCE('A', 'B', NULL, 'D', 'E') result FROM DUAL; /*Can have n number of values and returns first NOT NULL value ('A')*/
SELECT COALESCE(NULL, NULL, 'C', 'D') result FROM DUAL; /*Can have n number of values and returns first NOT NULL value ('C')*/
10. Difference between RANK and DENSE RANK
SELECT salary
,RANK() OVER(ORDER BY sal DESC) rank
,DENSE_RANK() OVER(ORDER BY sal DESC) dense_rank
FROM emp;| SALARY | RANK | DENSE_RANK |
| 1000 | 1 | 1 |
| 2000 | 2 | 2 |
| 2000 | 2 | 2 |
| 3000 | 4 | 3 |
| 4000 | 5 | 4 |
| 5000 | 6 | 5 |
| 5000 | 6 | 5 |
| 5000 | 6 | 5 |
| 6000 | 9 | 6 |
11. Types of SQL commands
| DDL | DML | DCL | TCL | DRL |
| CREATE | INSERT | GRANT | COMMIT | SELECT |
| ALTER | UPDATE | REVOKE | ROLLBACK | |
| DROP | DELETE | SAVEPOINT | ||
| TRUNCATE | MERGE | |||
| RENAME |
Session control statement : ALTER SESSION
System control statement : ALTER SYSTEM
12. How to get unique records without using DISTINCT keyword
We have nine ways to achieve this:
i) Using GROUP BY clause
SELECT a, b, c FROM table_name GROUP BY a, b, c;ii) Using set operator – UNION (Impacts performance)
SELECT a, b, c FROM table_name
UNION
SELECT a, b, c FROM table_name;iii) Using set operator – UNION
SELECT a, b, c FROM table_name
UNION
SELECT NULL, NULL, NULL FROM dual WHERE 1 = 2;iv)Using set operator – INTERSECT
SELECT a, b, c FROM table_name
INTERSECT
SELECT a, b, c FROM table_name;v) Using set operator – MINUS
SELECT a, b, c FROM table_name
MINUS
SELECT NULL, NULL, NULL FROM dual;vi) Using analytic function – ROW_NUMBER
SELECT a, b, c FROM (SELECT a, b, c, ROW_NUMBER() over(partition by a, b, c ORDER BY a, b, c) R FROM table_name)
WHERE R = 1;vii) Using analytic function – RANK
SELECT a, b, c FROM (SELECT a, b, c, RANK() over(partition by a, b, c ORDER BY ROWNUM) R FROM table_name)
WHERE R = 1;viii) Using ROWID
SELECT * FROM table_name
WHERE rowid IN (
SELECT MIN(rowid)
FROM table_name
GROUP BY a, b, c)
ORDER BY a, b, c;ix) Using co-related sub query
SELECT * FROM table_name a
WHERE 1 = (SELECT COUNT(1)
FROM table_name b
WHERE a.column_name1 = b.column_name1
AND a.column_name2 = b.column_name2
AND a.rowdid >= b.rowid);13. What is DUAL table – Dummy table automatically created by Oracle DB along with the data dictionary. It has only one column (dummy) with data type as VARCHAR2(1) and the value is ‘X’.
We can use this table for computational purposes like SELECT 1 + 2 FROM DUAL; SELECT 100*20 FROM DUAL; SELECT SYSDATE FROM DUAL; SELECT USER FROM DUAL;
We cannot use DECODE expression directly in PL/SQL block. We have to use in SELECT DECODE(a, b, c) INTO lv_col FROM DUAL;
14. What is Trigger and types of triggers
A trigger is a PL/SQL block which is automatically fired when an event occurs in the DB
| DML Trigger | DDL Trigger | SYSTEM Trigger | Instead of Trigger | Compound Trigger |
| INSERT | CREATE | LOGON | TRIGGER on Views | Combines DML Trigger in single block |
| UPDATE | ALTER | LOGOFF | Written on top of Views | Before/ after statement + before/ after row level |
| DELETE | DROP | STARTUP | ||
| TRUNCATE | SHUTDOWN | |||
| RENAME | ||||
| GRANT | ||||
| REVOKE | ||||
| AUDIT |
DML Trigger is classified into two types.
| Statement Level Trigger | Row Level Trigger |
| Trigger executes only once for all DML statements | Trigger executes for each and every row |
|
|
| Its 2 * 3 (2=BEFORE/ AFTER and 3 DML statements) ways we can execute | Its 2 * 3 (2=BEFORE/ AFTER and 3 DML statements) ways we can execute |
Execution order:
1. Before Statement level
2. Before Row level
3. After Row level
4. After Statement level
15. Difference between DECODE and CASE
Both serves the IF..ELSE functionality but CASE has more advanced features than DECODE
| DECODE | CASE |
| Oracle Standard | ANSI SQL-92 standard |
| Only can be check for equality | Can be used for logical and relational operators |
| Slower | Faster |
| Can be used in PLSQL via SQL statement | Can be directly used in PLSQL |
|
|
|
|
|
|
|
|
|
The below will not work due to datatype inconsistency
|
|
|
The below will not work as DECODE cannot be used as assignment varible
|
|
|
|
16. Difference between TRANSLATE and REPLACE
| TRANSLATE | REPLACE |
| Replace character by character in a string | Replace sequence of characters in a string |
Also used to remove ascii characters. When user gives space bar or press enter button in data field then ascii characters like CHR(10) or CHR(13) inserts into DB. To remove those acsii character we use REPLACE.
|
|
|
|
|
|
|
|
|
|
|
|
|
17. Views, Simple View and Complex View
View – Is a logical table created on top of one or more base tables or views. View does not have data of this own and it fetches data from base tables which it was defined. Syntax: CREATE OR REPLACE VIEW view_name AS SELECT statement;
CREATE OR REPLACE FORCE VIEW view_10 AS SELECT * FROM emp WHERE deptno = 10;FORCE is used to create a view even though base tables do not exist. In case we are creating view first and then base table then we have to use FORCE keyword.
SELECT * FROM view_10;CREATE OR REPLACE VIEW emp_sal_view
AS SELECT deptno, max(sal) max_sal, avg(sal) avg_sal, min(sal) min_sal FROM emp GROUP BY deptno;Query to get views in DB
SELECT * FROM user_views;Query to get column details of View
SELECT * FROM user_tab_columns WHERE table_name = 'EMP_SAL_VIEW';| Simple View | Complex View |
| Based on single table | Based on any number of tables |
| No aggregate / group functions (No GROUP BY clause) | Can use aggregate/group functions |
| No DISTINCT keyword | Can use DISTINCT keyword |
| No Pseudo columns. No Analytic functions. | Can use Pseduo columns. Can use analytic functions. |
| DML’s are allowed | No DML’s are allowed |
Question: If we add a NEW column to base table, will that column get added to view:
Answer: No. Suppose we are trying to create a view as below:
CREATE OR REPLACE VIEW emp_view AS SELECT * FROM emp;
Here the * gets replaced with individual columns while creating a view so no new columns will be added to view when we add new column to base table. We can verify this * replacement using user_views table.
They need to recreate using CREATE OR REPLACE VIEW syntax or using ALTER statement. Even view will not throw an error and execute with old columns.
Question: If we drop an existing column from base table, what will happen to view.
Answer: The view wont execute and will error out.
Question: How to check list of objects used in a view:
Answer: SELECT * FROM user_dependencies WHERE name = ‘view_name’;
Question: How to compile or recompile a view:
Answer:
1) CREATE OR REPLACE VIEW…
2) ALTER VIEW view_name COMPILE;
3) Try dropping a column and add back again in base table. Sometimes SELECT * FROM view_name; also gets recompiled
Question: If we create a view before creating base table using ‘FORCE VIEW’, how the columns get defined in a view.
Answer: View gets created with * and recompile using any of above three methods
Question: When we will use ‘FORCE’ view in real time:
1) No table dependencies
2) Can create view any time during installation process
18. Difference between View and Materialized View
| View | Materialized View |
| Logical table which does not have data. | Stores the data of the result set (query) physically. |
| SELECT * FROM view — Fetches data from base table | SELECT * FROM materialized_view — Fetches data from physical location |
| Any change on base table data reflects immediately on view. | REFRESH command helps to update MV data. |
|
|
View:
1) View is considered as a Logical table and it does not contain any data physically but behaves as if it contains data.
2) View always contains a query hence we can consider that a view is a schema object that stores the SELECT statement permanently in the DB.
3) Because of View we can reuse SELECT statement multiple times within the application development increasing productivity and reducing the production cost and maintenance cost.
4) We cannot create INDEX’s on View since they are not actual tables.
5) Views will create a logical layer providing security for the physical location of the DB objects and the actual structure of the actual DB object
6) Views can be either relational views or object views by creation and implementation.
7) Views can be FORCE or NOFORCE views by creation
8) Views can be READONLY views as well as WITH CHECK OPTION views
9) Even though a view contains only a SELECT statement, we can conduct transactions through views upon the original tables by following certain rules.
Materialized Views:
1) MV also contains a SELECT statement but once created it manages a physical table with replication of the queried data.
2) MV can hold the query and data with REFRESH cycles on the data.
3) We can create index’s on MV
4) MV increases the performance of the data querying process in complicated aggregations, joins and filters
5) MV are mostly used in managing OLAP operations, to keep pre calculated and pre aggregated patterns of the data.
6) They cannot be replaced. They have to be dropped and recreated once again.
MV is a DB object which contains the results of query. When we create a MV, Oracle DB creates an internal table and at least one index. We go with MV when the SELECT query has summaries and multiple joins. The basic feature of MV is REFRESH. Here the data gets refreshed based on ON COMMIT or DEMAND.
SYNTAX:
- CREATE MATERIALIZED VIEW <schema.name>
- TABLESPACE <tablespace_name>
- BUILD IMMEDIATE
- REFRESH <FAST | COMPLETE | FORCE > ON <COMMIT | DEMAND>
- < USING INDEX | USING NO INDEX>
- INITRANS <integer>
- STORAGE CLAUSE
- AS (<SQL statement>);
Build Methods:
BUILD IMMEDIATE: Create the materialized view and then populate it with data.
BUILD DEFFERED: Create the materialized view definition but do not populate it with data.
ON PREBUILT TABLE: use an existing table as view source
Refresh Types:
FAST: Apply the changes made since the last refresh.
COMPLETE: Truncate the existing data and re-insert new data.
FORCE: First tries to refresh with fast mechanism if possible or else will use a complete refresh. This is default refresh type.
NEVER: Suppresses all refreshes on materialized views.
Refresh Modes:
Manual Refresh: Can be performed using DBMS_MVIEW package. (REFRESH, REFRESH_DEPENDENT, REFRESH_ALL_VIEWS)
Automatic Refresh: Can be performed in two ways:
a) ON COMMIT – MV gets updated whenever changes to one of these tables are committed.
b) ON DEMMAND – At Specified Time – Refresh is scheduled to occur for specified time by using START WITH & NEXT clauses. For such refreshes, instance must initiate a process with JOB_QUEUE_PROCESSES.
Index Modes:
USING INDEX – Uses to create values for INITRANS (number of entries) and STORAGE (storage space) parameters. If USING INDEX is not specified, then default values are used for the index
USING NO INDEX Clause
Specify USING NO INDEX to suppress the creation of the default index.
19. Pseudo columns, Aggregate or Group functions, Analytic functions
| Pseudo columns | Aggregate or Group functions | Analytic functions | |||
| Pseudo columns behave like a normal table columns but the values are actually not stored in table. | Multiple records are joined together to get single value | RANK
|
|||
| Only SELECT operation can performed but no DML operations. | SUM | DENSE_RANK
|
|||
| CURRVAL | COUNT | ROW_NUMBER | |||
| NEXTVAL | MAX | LEAD | |||
| LEVEL | MIN | LAG | |||
| ROWID | AVG | FIRST | |||
| ROWNUM | LAST | ||||
| FIRST_VALUE | |||||
| LAST_VALUE | |||||
| LISTAGG | |||||
| NTH_VALUE |
20. Features of Oracle 12.2
i) Object name greater than 30 characters
ii) Utilizing LISTAGG function for string greater than 4000 characters
iii) Session sequence. This is 12.1 feature
iv) DDL Logging. This is 12.1 feature
v) JSON functions
20.1 Object name greater than 30 characters
• Maximum length of object name in 12C is 128 bytes
• This is achievable from database 12.2 version on wards. To know your current version use SELECT * FROM v$version;
• The compatible initialization parameter must be set to 12.2.0 or higher. SELECT value FROM v$parameter WHERE name = ‘compatible’;
• To know the object length in your database describe ‘user_tables’ and see the datatype of column ‘TABLE_NAME’
20.2 Utilizing LISTAGG function for string greater than 4000 characters
From 12.2 if the string length is > 4000 then we have two options to return output.
i) Throw an error : Same error which we get when the length exceeds 4000 characters
SELECT LISTAGG(table_name
,'||' ON OVERFLOW ERROR) WITHIN GROUP(
ORDER BY table_name) table_names
FROM all_tables;ii) Truncate the data
SELECT LISTAGG(table_name
,'||' ON OVERFLOW TRUNCATE) WITHIN GROUP(
ORDER BY table_name) table_names
FROM all_tables;
--The last ... denotes still more data exists and (number) denotes the number of truncated fields.
--The ... and number can be replaced by using below query
SELECT LISTAGG(table_name
,'||' ON OVERFLOW TRUNCATE '**Some more data exists**' WITHOUT count) WITHIN GROUP(
ORDER BY table_name) table_names
FROM all_tables;
--No custom message and no number
SELECT LISTAGG(table_name
,'||' ON OVERFLOW TRUNCATE '' WITHOUT count) WITHIN GROUP(
ORDER BY table_name) table_names
FROM all_tables;20.3 Session sequence
In a particular session we get reset sequences. This is 12.1 feature.
Ex: Session 1 — Sequence 1, 2, 3…; Session 2 — Sequence 1, 2, 3…; Session 3 — Sequence 1, 2, 3…
CREATE SEQUENCE sequence_name SESSION;
The default sequence what we use is GLOBAL sequence and no need to explicitly define while creating sequence. CREATE SEQUENCE sequence_name; = CREATE SEQUENCE sequence_name GLOBAL;
20.4 DDL Logging
From 12.1, we can capture the log files for DDL commands during deployment.
ALTER SYSTEM SET ENABLE_DDL_LOGGING = TRUE;
ALTER SESSION SET ENABLE_DDL_LOGGING = TRUE;
DDL log file location:
<oracle_home_directory>\diag\rdbms\orcl12c\orcl12c\log\ddl
Log files:
1. Text file
2. XML file
20.5 JSON functions
JSON = Java Script Object Notation
JSON document:
{“ENAME”:”SCOTT”}
{“ENAME”:”KING”, “ENAME”:”BLAKE”, “ENAME”:”CLARK”}
{“Emp List”:[“KING”, “BLAKE”, “CLARK”]}
21. SQL query to return nth highest record or <nth records
Replace < 5 with = 5 to get 5th highest record
1. SELECT * FROM (SELECT * FROM emp ORDER BY SAL DESC) WHERE ROWNUM < 5;
2. SELECT e.* FROM emp e, (SELECT empno, ROW_NUMBER () OVER (ORDER BY sal DESC) row_num FROM emp) b WHERE b.row_num < 5 AND b.empno = e.empno;
3. WITH b AS (SELECT empno, ROW_NUMBER () OVER (ORDER BY sal DESC) row_num FROM emp)
SELECT e.* FROM emp e, b WHERE b.row_num < 5 AND b.empno = e.empno;
4. SELECT * FROM emp ORDER BY sal DESC FETCH FIRST 4 ROWS ONLY;22. Index
An index is a database object and is used to speed up the search operation in the database. For example a standard book contains an Index/Contents and if we want to go to particular page then with the help of index we go to that page directly avoiding full book search. Similarly an index in DB contains a pointer which points to the row containing the value avoiding full table scan. Also index sorts the data in ascending order and helps faster retrieval of data. Indexes are used for performance improvement.
SELECT * FROM user_indexes WHERE table_name = 'EMP';
SELECT * FROM user_ind_columns WHERE table_name = 'EMP';
SELECT * FROM user_ind_statistics WHERE table_name = 'EMP';Types
| B-Tree | Bitmap | Function Based | Reverse Key | Composite |
| Create on column which has more number of unique/ distinct values | Create on column which has less number of unique/ distinct values | UPPER or LOWER functions | The key index values will be reversed | Multiple columns |
| Ex: EMPNO | Ex: DEPTNO or Gender(Male/ Female) or Status (Active/ Inactive) | Avoid index block contention. | ||
| B means balanced. Sorts the values and divides into gropus. Say we have 14 empno. 1 to 7 will be one group and 8 to 14 will be in one group. Again 1 to 7 or 8 to 14 will spilt into group like 1 to 3 and 4 to 7. This avoid full table scan. | ||||
| The indexed column along with rowid column will be stored in another data set for faster retrieval of data. | ||||
| CREATE INDEX idx_name ON tbl_name(col_name); | CREATE BITMAP INDEX idx_name ON tbl_name(col_name); | CREATE INDEX idx_name ON tbl_name(UPPER(col_name)); | CREATE INDEX idx_name ON tbl_name(col_name) REVERSE; | CREATE INDEX idx_name ON tbl_name(col_name1, col_name2); |
| In user_indexes table the index_type = NORMAL | ||||
| Hampers DML operations. |
Check if index is used by query:
The first example has index unique scan due to empno in WHERE clause whereas in second example we have full table scan since no index on deptno column.
Example 1:
EXPLAIN PLAN FOR SELECT * FROM emp WHERE empno=7839;
SELECT * FROM table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
Plan hash value: 2949544139
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7839)
Example 2:
EXPLAIN PLAN FOR SELECT * FROM emp WHERE deptno=10;
SELECT * FROM table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 114 | 2 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| EMP | 3 | 114 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("DEPTNO"=10)
Also we can verify using tables v$sql and v$sql_plan;
Scan Types/ Operations
i) Range scan
ii) Unique scan
iii) Full scan
iv) Full scan (Max/ Min)
v) Fast full scan
23. EXISTS
Exists returns a Boolean value (True or False).
SELECT * FROM abc a WHERE EXISTS (SELECT c1 FROM xyz x WHERE x.some_id = a.some_id);
24. DML error logging tables
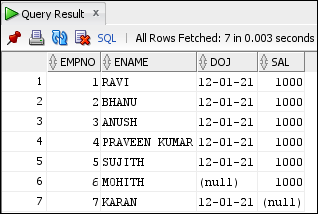
Assume we are trying to insert 10 records into table and 7th record failed due to some issues. The failed record should be captured in one (error) table and other records should insert into table. To achieve this we use DML error logging table.
Usually in Oracle if one record fails others wont insert. One fail == all fail.
CREATE TABLE source_emp (
empno NUMBER PRIMARY KEY,
ename VARCHAR2(30),
doj DATE,
sal NUMBER
);
INSERT INTO source_emp(empno, ename, doj, sal) VALUES(1, 'RAVI', SYSDATE, 1000);
INSERT INTO source_emp(empno, ename, doj, sal) VALUES(2, 'BHANU', SYSDATE, 1000);
INSERT INTO source_emp(empno, ename, doj, sal) VALUES(3, 'ANUSH', SYSDATE, 1000);
INSERT INTO source_emp(empno, ename, doj, sal) VALUES(4, 'PRAVEEN KUMAR', SYSDATE, 1000);
INSERT INTO source_emp(empno, ename, doj, sal) VALUES(5, 'SUJITH', SYSDATE, 1000);
INSERT INTO source_emp(empno, ename, doj, sal) VALUES(6, 'MOHITH', NULL, 1000);
INSERT INTO source_emp(empno, ename, doj, sal) VALUES(7, 'KARAN', SYSDATE, NULL);
COMMIT;
SELECT * FROM source_emp;
CREATE TABLE target_emp (
empno NUMBER PRIMARY KEY,
ename VARCHAR2(10),
doj DATE NOT NULL,
sal NUMBER NOT NULL
);
INSERT INTO target_emp (SELECT * FROM source_emp);
Error starting at line : 33 in command -
INSERT INTO target_emp (SELECT * FROM source_emp)
/*Error report -
ORA-12899: value too large for column "ORADB"."TARGET_EMP"."ENAME" (actual: 13, maximum: 10)*/
BEGIN
dbms_errlog.create_error_log(dml_table_name=>'target_emp');
END;
/*The above block will create an error table as err$_target_emp*/
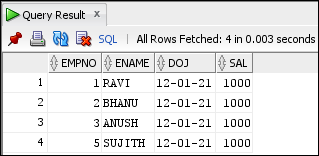
INSERT INTO target_emp (SELECT * FROM source_emp)
LOG ERRORS INTO err$_target_emp ('error in insert statement') REJECT LIMIT UNLIMITED;
/*4 rows inserted*/
UPDATE target_emp SET sal = NULL WHERE empno = 1
LOG ERRORS INTO err$_target_emp ('error in update statement') REJECT LIMIT UNLIMITED;
/*0 rows updated*/
CREATE OR REPLACE TRIGGER errlog_delete
BEFORE DELETE ON target_emp FOR EACH ROW
DECLARE
ln_temp NUMBER;
BEGIN
ln_temp := 1/0;
END;
DELETE FROM target_emp WHERE empno = 1
LOG ERRORS INTO err$_target_emp ('error in delete statement') REJECT LIMIT UNLIMITED;
/*0 rows deleted*/
SELECT * FROM target_emp;
SELECT * FROM err$_target_emp;

25. NOCOPY Hint
→ What is ‘Actual’ and ‘Formal’ Parameters
→ What is ‘Pass by value’ and ‘Pass by reference’
→ What is ‘NOCOPY’ hint
→ How ‘NOCOPY’ improves performance
→ What is ‘Actual’ and ‘Formal’ Parameters
Parameters which are defined while creation of procedure or function are formal parameters. The values which are being passed while calling procedure or function are actual parameters. Both the parameters have their own memory location and the data gets transferred from actual –> formal –> actual and this impacts performance.
CREATE OR REPLACE PROCEDURE formal_parameter_proc (
p_formal_parameter IN OUT VARCHAR2 --Here p_formal_parameter is formal parameter
) IS
BEGIN
p_formal_parameter := 'B';
END;
CLEAR SCREEN;
SET SERVEROUTPUT ON;
DECLARE
lv_var VARCHAR2(1);
BEGIN
lv_var := 'A';
formal_parameter_proc(lv_var); --lv_var is Actual parameter
dbms_output.put_line('lv_var: ' || lv_var);
END;
--lv_var: B
--The memory location of actual parameter is overwritten with formal parameter.
--The values will be copied back to actual parameter only on successful execution of procedure
--The below procedure will be errored due to 1/0 error
CREATE OR REPLACE PROCEDURE formal_parameter_proc (
p_formal_parameter IN OUT VARCHAR2
) IS
lv_temp NUMBER;
BEGIN
p_formal_parameter := 'B';
lv_temp := 1 / 0;
END;
CLEAR SCREEN;
SET SERVEROUTPUT ON;
DECLARE
lv_var VARCHAR2(1);
BEGIN
lv_var := 'A';
BEGIN
formal_parameter_proc(lv_var); --lv_var is Actual parameter
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
dbms_output.put_line('lv_var: ' || lv_var);
END;
--lv_var: A
--The value B will not be passed to A due to error in procedure
--Using NOCOPY hint(Pass by reference)
CREATE OR REPLACE PROCEDURE formal_parameter_proc (
p_formal_parameter IN OUT NOCOPY VARCHAR2
) IS
lv_temp NUMBER;
BEGIN
p_formal_parameter := 'B';
lv_temp := 1 / 0;
END;
CLEAR SCREEN;
SET SERVEROUTPUT ON;
DECLARE
lv_var VARCHAR2(1);
BEGIN
lv_var := 'A';
BEGIN
formal_parameter_proc(lv_var); --lv_var is Actual parameter
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
dbms_output.put_line('lv_var: ' || lv_var);
END;
--lv_var: B
--NOCOPY uses single memory location so returned B
→ What is ‘Pass by value’ and ‘Pass by reference’
1. NOCOPY hint is applicable for OUT and INOUT parameters only.
2. ‘Pass by Value’ copies the value from actual parameter to formal parameter and copies back the formal parameter back to actual parameter only on successful execution of calling program.
3. In case if there is an exception raised in (calling program) ‘Pass by Value’ method, then the actual parameter is guaranteed to hold the actual values passed to calling program.
4. ‘Pass by Reference’ can be achieved by specifying the ‘NOCOPY’ hint as a part of parameter definition, where both the actual parameter and formal parameter will refer to the same memory location during execution.
5. In case if there is an exception raised in (calling program) ‘Pass by Reference’ method, since both the actual and formal parameter shares the same memory location, there is no guarantee that the actual parameter holds the value passes to the calling program.
6. In ‘Pass by Reference’ method you will not see any performance difference if you test on scalar parameters like number, char..etc. However you will see significant difference if the parameter hold huge volume of data like collections or LOB values.
→ What is ‘NOCOPY’ hint – NOCOPY is a hint provided to compiler to use ‘Pass By Reference’.
→ How ‘NOCOPY’ improves performance
The same memory location will be shared while using NOCOPY
CREATE OR REPLACE PACKAGE demo_package AS
TYPE nest_tab_type IS
TABLE OF VARCHAR2(4000);
lv_nest_tab_var nest_tab_type := nest_tab_type();
PROCEDURE p_copy (
param_value IN OUT nest_tab_type
);
PROCEDURE p_nocopy (
param_value IN OUT NOCOPY nest_tab_type
);
END;
-----------------------------------------------------
CREATE OR REPLACE PACKAGE BODY demo_package AS
PROCEDURE p_copy (
param_value IN OUT nest_tab_type
) AS
x NUMBER;
BEGIN
NULL;
END;
PROCEDURE p_nocopy (
param_value IN OUT NOCOPY nest_tab_type
) AS
x NUMBER;
BEGIN
NULL;
END;
END;
CLEAR SCREEN;
SET SERVEROUTPUT ON;
DECLARE
lv_last_idx NUMBER;
lv_start_time NUMBER;
lv_end_time NUMBER;
BEGIN
FOR i IN 1..20000 LOOP
demo_package.lv_nest_tab_var.extend;
lv_last_idx := demo_package.lv_nest_tab_var.last();
demo_package.lv_nest_tab_var(lv_last_idx) := lpad('A', 4000, 'A');
END LOOP;
lv_start_time := dbms_utility.get_time;
demo_package.p_copy(demo_package.lv_nest_tab_var);
lv_end_time := dbms_utility.get_time;
dbms_output.put_line('Copy Time = ' ||(lv_end_time - lv_start_time)||' milli seconds');
lv_start_time := dbms_utility.get_time;
demo_package.p_nocopy(demo_package.lv_nest_tab_var);
lv_end_time := dbms_utility.get_time;
dbms_output.put_line('No Copy Time = ' ||(lv_end_time - lv_start_time)||' milli seconds');
END;
--Copy Time = 8 milli seconds
--No Copy Time = 0 milli seconds
26. Exclude duplicate records while insertion
i) Use DML error log table (24. DML error logging tables)
ii) Use ‘IGNORE_ROW_ON_DUPKEY_INDEX’ hint
INSERT /*+ IGNORE_ROW_ON_DUPKEY_INDEX(target_table(column_name)) */ INTO target_table SELECT * FROM source_table;
iii) MERGE statement
MERGE INTO emp_target USING emp_source ON (emp_source.empno = emp_target.empno) WHEN NOT MATCHED THEN INSERT (empno, ename) VALUES (emp_source.empno, emp_source.ename);
iv) Set operator
INSERT INTO emp_target SELECT * FROM emp_source MINUS SELECT * FROM emp_target;
v) Subquery
INSERT INTO emp_target SELECT * FROM emp_source WHERE empno NOT IN (SELECT empno FROM emp_target);
27. Interface types
i) SQL *Loader
a) Basic Structure
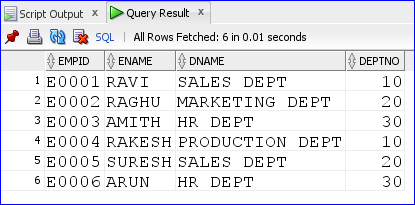
/*control_file.ctl*/ OPTIONS(SKIP=1) LOAD DATA INFILE 'data_file.txt' TRUNCATE INTO TABLE emp_details /*Valid functions are TRUNCATE, INSERT, REPLACE and APPEND*/ FIELDS TERMINATED BY ',' ( EMPID, ENAME, DNAME, DEPTNO )
/*data_file.txt*/ EMPID,ENAME,DNAME,DEPTNO E0001,RAVI,SALES DEPT,10 E0002,RAGHU,MARKETING DEPT,20 E0003,AMITH,HR DEPT,30 E0004,RAKESH,PRODUCTION DEPT,10 E0005,SURESH,SALES DEPT,20 E0006,ARUN,HR DEPT,30
DROP TABLE emp_details; CREATE TABLE emp_details( empid VARCHAR2(30), ename VARCHAR2(30), dname VARCHAR2(30), deptno NUMBER ); /*In command prompt execute as below*/ /*C:\MyWorks\EBSGUIDE\SQLLDR>sqlldr ORADB/oracle123@XE control=control_file.ctl*/ SELECT * FROM emp_details;
b) To skip specific column use keyword FILLER in .ctl file and to skip specific row use WHEN clause in .ctl file
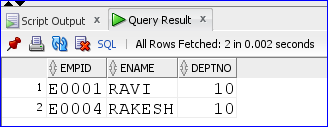
/*control_file.ctl*/ OPTIONS(SKIP=1) LOAD DATA INFILE 'data_file.txt' TRUNCATE INTO TABLE emp_details WHEN DEPTNO = '10' /*Only = or <> can be used and also remove this comment*/ FIELDS TERMINATED BY ',' ( EMPID, ENAME, DNAME FILLER, DEPTNO )
/*data_file.txt*/ EMPID,ENAME,DNAME,DEPTNO E0001,RAVI,SALES DEPT,10 E0002,RAGHU,MARKETING DEPT,20 E0003,AMITH,HR DEPT,30 E0004,RAKESH,PRODUCTION DEPT,10 E0005,SURESH,SALES DEPT,20 E0006,ARUN,HR DEPT,30
DROP TABLE emp_details; CREATE TABLE emp_details( empid VARCHAR2(30), ename VARCHAR2(30), deptno NUMBER ); /*In command prompt execute as below*/ /*C:\MyWorks\EBSGUIDE\SQLLDR>sqlldr ORADB/oracle123@XE control=control_file.ctl*/ SELECT * FROM emp_details;
| Multiple data files data can be loaded into one single table | One single data file data can be loaded into multiple files |
LOAD DATA INFILE file1.dat INFILE file2.dat INFILE file3.dat APPEND INTO emp ( empno POSITION(1:4) INTEGER EXTERNAL, ename POSITION(6:15) CHAR, dname POSITION(17:25) CHAR ) |
LOAD DATA INFILE * INTO TABLE tab1 WHEN tab = 'tab1' ( tab FILLER CHAR(4), col1 INTEGER ) INTO TABLE tab2 WHEN tab = 'tab2' ( tab FILLER POSITION(1:4), col1 INTEGER ) |
ii) UTL_FILE package
iii) External Table
iv) iSetup
1. DBA Task: Make sure to copy the DBC file in the FND_SECURE path in both the instances to establish a link between two instances.
2. Same user should exist in both the instances.
3. Ensure iSetup responsibility is assigned to user in both the instances.
4. Create instance mapping
5. Create selection sets
6. Create extracts
7. Create Loads
8. Load data into target instance
v) Data Loader
More like a record and play. DataLoader will be excel like sheet and based on key strokes we should be able to create data in EBS. Delay plays a vital role.
vi) Web ADI
• Create Integrator
• Create Interface
• Create Layout
• Preview
• Create Function for WebADI
• Attach function to responsibility
• Attach function to WebADI
CREATE TABLE xx_ap_invoice (
p_sup_name VARCHAR2(50),
p_sup_site VARCHAR2(50),
p_invoice_num VARCHAR2(50),
p_inv_amount VARCHAR2(50),
p_inv_date VARCHAR2(50),
p_inv_currency VARCHAR2(50),
p_payment_currency VARCHAR2(50),
p_inv_source VARCHAR2(50)
);
CREATE OR REPLACE PACKAGE xx_webadi_pkg AS
PROCEDURE load_data (
p_sup_name VARCHAR2,
p_sup_site VARCHAR2,
p_invoice_num VARCHAR2,
p_inv_amount VARCHAR2,
p_inv_date VARCHAR2,
p_inv_currency VARCHAR2,
p_payment_currency VARCHAR2,
p_inv_source VARCHAR2
);
CREATE OR REPLACE PACKAGE BODY xx_webadi_pkg AS
PROCEDURE load_data (
p_sup_name VARCHAR2,
p_sup_site VARCHAR2,
p_invoice_num VARCHAR2,
p_inv_amount VARCHAR2,
p_inv_date VARCHAR2,
p_inv_currency VARCHAR2,
p_payment_currency VARCHAR2,
p_inv_source VARCHAR2
) IS
BEGIN
INSERT INTO xx_ap_invoice VALUES (
p_sup_name,
p_sup_site,
p_invoice_num,
p_inv_amount,
p_inv_date,
p_inv_currency,
p_payment_currency,
p_inv_source
);
COMMIT;
END;
END;
Create Integrator:
Desktop Integration Manager responsibility > Manage Integrators > Create Integrator
Integrator Name: XX AP WebADI Integrator
Internal Name: XX_AP_WEDADI_INT
Application: Payables
Enabled: Yes
Tick Display in Create Document Page
Click on Add Functions > Search By: Code; Value: BNE%DOC% > Select both the servlets (BNE_ADI_CREATE_DOCUMENT & BNE_CREATE_DOCUMENT) > Next
Create Interface:
Interface Name:XX_WEBADI_INTERFACE
Interface Type: API Procedure
Package Name: xx_webadi_pkg
Procedure/ Function Name: LOAD_DATA
API Returns: FND Message Code
Apply
Select Interface Name > Review attributes (same as procedure parameters) > Next > Select Content Name as NONE > Next > Uploader: None > Next > Submit
Create Layout:
Search for integrator name > Select integrator > Click on Define Layout > Create > Layout Name: XX_WEBADI_LAYOUT; Number of Headers: 1 > Next > Change the Placement value to Line for all fields > Next > Maintain default values > Apply
Preview:
Desktop Integration Manager responsibility > Manage Integrators > Search for your integrator > Select integrator and click on Preview > Next > Create Document > Open File with > Excel gets opened > Enter values as below:
SUP_NAME: ABC Corporation
SUP_SITE: HYD
INVOICE_NUM: INV123
INV_AMOUNT: 100
INV_DATE:01-JAN-2021
INV_CURRENCY: USD
PAYMENT_CURRENCY: USD
INV_SOURCE:MANUAL
Click Oracle > Upload > Verify confirmation message
The records inserted into staging table: xx_ap_invoice 🙂
Create Function for WebADI
System Administrator > Application > Function
Function: XX_AP_WEBADI_FUNCTION
User Function Name: XX AP WebADI Integrator
Type:SSWA servlet function
Maintenance Mode Support: None
Context Dependence: Responsibility
Under the Form tab
Paste the Parameter value as below after changing the integrator_code, layout_code and content_code. Execute the below query to get all details for your parameter.
SQLAP –> Application short name of Integrator, We can use application id instead of short name.
bne:page=BneCreateDoc&bne:viewer=BNE:EXCEL2007&bne:reporting=N&bne:integrator=SQLAP:CDMXX_WEBADI_INTGR_XINTG&bne:layout=SQLAP:CDMXX_WEBADI_LO&bne:content=SQLAP:CDMXX_WEBADI_INTGR_CNT1&bne:noreview=Y
SELECT biv.application_id
,biv.integrator_code
,biv.user_name
,bib.interface_code,lo.LAYOUT_CODE,
(select user_name from BNE_LAYOUTS_TL where LAYOUT_CODE=lo.LAYOUT_CODE) layoutname,
(select user_name from BNE_CONTENTS_TL where content_code=cont.content_code) contentname,
cont.content_code,
cont.param_list_code,
cont.content_class,(SELECT QUERY FROM BNE_STORED_SQL WHERE CONTENT_CODE=CONT.CONTENT_CODE)QUERY
FROM bne_integrators_vl biv
,bne_interfaces_b bib,
BNE_LAYOUTS_B lo,
BNE_CONTENTS_b cont
WHERE upper(user_name) like ‘%your intergrator name%’
AND bib.integrator_code = biv.integrator_code
and lo.integrator_code = biv.integrator_code
and cont.integrator_code = biv.integrator_code
Enter value for HTML Call as “BneApplicationService” under Web HTML
Attach function to responsibility menu
Go to System Administrator –> Application –> Menu
Query your menu > Add one more row
Select the function name “XX_AP_WEBADI_FUNCTION” which we created now. Put the same name for Prompt as well
Attach function to WebADI
Go to Desktop Integration Manager –> Manage Integrators –> Query the Integrator Name –> Select the update option –> Add Functions. Add the function name “XX_AP_WEBADI_FUNCTION”. Verify the Integrator.
Check the responsibility 🙂
28. Difference Between VARCHAR and VARCHAR2
| VARCHAR | VARCHAR2 | |
| Size | Stores characters upto 2000 bytes | Stores characters upto 4000 bytes |
| Memory | Memory wastage happens as free space occupied with NULL characters. lv_ename VARCHAR(10); lv_ename := ‘KING’; 6 NULL characters will be occupied |
No memory wastage happens as releases unused space. lv_ename VARCHAR(10); lv_ename := ‘KING’; Only 4 bytes occupied. |
29. Difference between WHERE and HAVING
| WHERE | HAVING | GROUP BY |
| Filter rows | ||
| Works on row’s data. Not on aggregated data | Works on aggregated data | Used with aggregate functions |
| SELECT * FROM emp WHERE sal > 5000; | SELECT MAX(sal) FROM emp HAVING sal > 5000; | SELECT MAX(sal), deptno FROM emp WHERE 1=1 GROUP BY deptno HAVING deptno > 10; |
Aggregated functions:
1) SUM, MAX, MIN, AVG and COUNT
2) To perform calculations on multiple rows of a single column
3) Returns a single value
30. EBS Cycles
| Process | Tables | Types | Concurrent Programs |
| Item | mtl_system_items_b msib mtl_system_items_tl msit |
||
| Supplier | ap_suppliers as ap_supplier_sites_all assa ap_supplier_contacts asc |
||
| Buyer | per_all_people_f papf per_all_assignments_f paaf |
||
| Requisition | po_requisition_headers_all prha po_requisition_lines_all prla po_req_distributions_all prda |
i) Standard – Within organisation and no approval required. ii) Purchase – External organisation and approval required. |
|
| Request for Quotation | po_headers_all pha WHERE pha.type_lookup_code = ‘RFQ’ |
i) Standard – One time purchasing ii) Bid – Expensive/ Large number of items iii) Catalog – Regular purchasing |
|
| Quotation | po_headers_all pha WHERE pha.type_lookup_code = ‘QUOTATION’ |
||
| Purchase Order | po_headers_all pha po_lines_all pla po_distributions_all pda po_line_locations_all plla |
i) Standard – One time purchasing ii) Blanket – Agreement iii) Planned – Long term agreement iv) Contract – Terms & conditions |
|
| Goods Receipt Note | rcv_shipment_headers rsh rcv_shipment_lines rsl rcv_transactions rt |
||
| AP Invoice | ap_invoices_all aia ap_invoice_lines_all aila ap_invoice_distributions_all aida |
Pay on Receipt AutoInvoice | |
| Payments of Invoice | ap_checks_all aca ap_invoice_payments_all aipa ap_payment_schedules_all apsa |
||
| Journals & Posting | gl_je_batches gjb gl_je_headers gjh gl_je_lines gjl gl_balances gb |
||
| Customers | hz_parties hp hz_party_sites hps hz_party_site_uses hpsu hz_cust_accounts hca hz_cust_account_sites hcas hz_cust_account_site_uses hcasu hz_locations hlhp.party_type IN (‘PERSON’, ‘ORGANIZATION’, ‘GROUP’) |
||
| Enter Sales Order | oe_order_headers_all ooha oe_order_lines_all oola |
||
| Book Sales Order | wsh_delivery_details wdd wsh_delivery_assignments wda |
||
| Launch Pick Release | wsh_delivery_details wdd wsh_delivery_assignments wda wsh_new_deliveries wnd |
i) Pick slip report ii) Shipping exception report iii) Auto pack report |
|
| Ship Confirm | wsh_delivery_details wdd | i) Interface trip stop ii) Commercial invoice iii) Packing slip report iv) Bill of lading |
|
| AR Invoice | ra_interface_lines_all rail ra_customer_trx_all rcta ra_customer_trx_lines_all rctla |
i) Workflow background process (OM to AR interface) ii) AutoInvoice Master (AR interface to AR base) |
|
| Receipt Creation | ar_receivable_applications_all araa ar_cash_receipts_all acra |
Manual or Auto Lockbox | |
| Journals & Posting | gl_je_batches gjb gl_je_headers gjh gl_je_lines gjl gl_balances gb |
i) Create Accounting |
31. Conversion or Interfaces
| Source File | Load into Staging Table | PLSQL Code (Validations) | Interface Table | Open Interface or API’s | Base Table |
| GL Journals | i. SQL * Loader (Control File in bin directory and source file in inbound path) ii. UTL_FILE UTL_FILE.FILE_TYPE; — Pointer to find the file location UTL_FILE.FOPEN; — Open the existing file or create a new file UTL_FILE.PUT_LINE; — Transfer data from DB to flat file UTL_FILE.GET_LINE; — Transfer data from flat file to DB UTL_FILE.FCLOSE; — Closes the file iii. External Table |
i. File name ii. Code combination iii. Period open iv. SUM(debit_amount) = SUM(credit_amount) else suspense account |
gl_interface | Journal Import | gl_je_batches gl_je_headers gl_je_lines |
| AP Invoices | Validate Invoice Number. Validate Vendor Name. Validate Vendor Number Validate Invoice Type Validate Invoice Amount Validate Payment Terms. Validate Payment Method. Validate GL Date. Validate Payment Reason Code. Validate Line Type. Validate Sum of Line Amount Validate POET (Project, Organization, Expenditure, Task). Validate Tax Code. Validate Operating Unit. Validate Exchange Rate. Validate Exchange Type. Validate Bank Account. Validate Tax Location and Tax Code. |
ap_invoices_interface ap_invoice_lines_interface ap_interface_rejections |
Payables Open Interface Import Program
API’s |
ap_invoices_all ap_invoice_lines_all ap_invoice_distributions_all |
|
| AR Invoices | i. Transaction Number ii. Legal Entity iii. Batch Source iv. Transaction Type v. Currency Code vi. Payment Terms vii. Bill To and Ship To Customer |
ra_interface_lines_all rail | AutoInvoice Master (AR interface to AR base)
API’s |
ra_customer_trx_all rcta ra_customer_trx_lines_all rctla |
|
| Supplier | i. Vendor Number ii. Tax Registration Number iii. OU Name |
ap_vendor_pub_pkg.create_vendor ap_vendor_pub_pkg.create_vendor_site ap_vendor_pub_pkg.create_vendor_contact iby_ext_bankacct_pub.create_ext_bank iby_ext_bankacct_pub.create_ext_bank_branch iby_ext_bankacct_pub.create_ext_bank_acct |
ap_suppliers as ap_supplier_sites_all assa ap_supplier_contacts asc |
||
| Customer | i. Customer name ii. Collector iii. Profile Class iv. Payment Terms |
hz_cust_account_v2pub.create_cust_account HZ_CUSTOMER_PROFILE_V2PUB.create_cust_profile_amt HZ_LOCATION_V2PUB.CREATE_LOCATION| HZ_PARTY_SITE_V2PUB.CREATE_PARTY_SITE |
hz_parties hp hz_party_sites hps hz_party_site_uses hpsu hz_cust_accounts hca hz_cust_account_sites hcas hz_cust_account_site_uses hcasu hz_locations hlhp.party_type IN (‘PERSON’, ‘ORGANIZATION’, ‘GROUP’) |
||
| HRMS | i. per_person_types ii. Organization iii. Location iv. Job v. Expense Account |
hr_employee_api.create_employee hr_assignment_api.update_emp_asg hr_assignment_api.update_emp_asg_criteria |
per_all_people_f papf per_all_assignments_f paaf |
32. Analyze
- Analyze command is used to perform various functions on index, table or cluster.
- Validates structure of an object
- Collects the statistics about the object
- Deletes the statistics that are used by an object
33. MERGE
Merge statement is used to combine the functionality of INSERT, UPDATE and DELETE in one statement. MERGE statement is used to select rows from one or more source tables for update or insert into target table or view. We can specify conditions to determine whether to update or insert into the target table or view. This statement is a convenient way to combine multiple operations. It lets you to avoid multiple INSERT, UPDATE and DELETE DML statements.
DROP TABLE emp_source; CREATE TABLE emp_source(empno NUMBER PRIMARY KEY, ename VARCHAR2(20), sal NUMBER(5)); INSERT INTO emp_source VALUES (1, 'RAVI', 1000); INSERT INTO emp_source VALUES (2, 'RAGHU', 2000); INSERT INTO emp_source VALUES (3, 'PRIYA', 3000); INSERT INTO emp_source VALUES (4, 'KAVIN', 4000); COMMIT; DROP TABLE emp_target; CREATE TABLE emp_target(empno NUMBER PRIMARY KEY, ename VARCHAR2(20), sal NUMBER(5)); INSERT INTO emp_target VALUES (1, 'RAVI', 1000); INSERT INTO emp_target VALUES (2, 'RAGHU', 2000); INSERT INTO emp_target VALUES (3, 'PRIYA', 3000); INSERT INTO emp_target VALUES (4, 'KAVIN', 4000); COMMIT; INSERT INTO emp_source VALUES(5, 'SUMAN', 5000); UPDATE emp_source SET sal = 3500 WHERE empno = 3; COMMIT; /*To sync emp_target table data with emp_source table we have to use one insert and one update. Rather a single MERGE statement resolves the purpose*/ UPDATE emp_target SET sal = (SELECT emp_source.sal FROM emp_source WHERE emp_source.empno = emp_target.empno); INSERT INTO emp_target (SELECT * FROM emp_source WHERE empno NOT IN (SELECT empno FROM emp_target)); ROLLBACK; MERGE INTO emp_target USING emp_source ON (emp_target.empno = emp_source.empno) WHEN MATCHED THEN UPDATE SET emp_target.sal = emp_source.sal WHEN NOT MATCHED THEN INSERT VALUES(emp_source.empno, emp_source.ename, emp_source.sal); COMMIT; /*--DELETE--*/ DROP TABLE emp_source; CREATE TABLE emp_source(empno NUMBER PRIMARY KEY, ename VARCHAR2(20), sal NUMBER(5), resigned VARCHAR2(1)); INSERT INTO emp_source VALUES (1, 'RAVI', 1000, NULL); INSERT INTO emp_source VALUES (2, 'RAGHU', 2000, NULL); INSERT INTO emp_source VALUES (3, 'PRIYA', 3000, NULL); INSERT INTO emp_source VALUES (4, 'KAVIN', 4000, NULL); COMMIT; DROP TABLE emp_target; CREATE TABLE emp_target(empno NUMBER PRIMARY KEY, ename VARCHAR2(20), sal NUMBER(5)); INSERT INTO emp_target VALUES (1, 'RAVI', 1000); INSERT INTO emp_target VALUES (2, 'RAGHU', 2000); INSERT INTO emp_target VALUES (3, 'PRIYA', 3000); INSERT INTO emp_target VALUES (4, 'KAVIN', 4000); COMMIT; INSERT INTO emp_source VALUES(5, 'SUMAN', 5000, NULL); UPDATE emp_source SET sal = 3500 WHERE empno = 3; UPDATE emp_source SET resigned = 'Y' WHERE empno = 1; COMMIT; MERGE INTO emp_target USING emp_source ON (emp_target.empno = emp_source.empno) WHEN MATCHED THEN UPDATE SET emp_target.sal = emp_source.sal DELETE WHERE emp_source.resigned = 'Y' WHEN NOT MATCHED THEN INSERT VALUES(emp_source.empno, emp_source.ename, emp_source.sal); COMMIT;
Error Handling
DROP TABLE emp_source; CREATE TABLE emp_source(empno NUMBER PRIMARY KEY, ename VARCHAR2(20), sal NUMBER(5));/*ename size is 20*/ INSERT INTO emp_source VALUES (1, 'RAVI', 1000); INSERT INTO emp_source VALUES (2, 'RAGHU', 2000); INSERT INTO emp_source VALUES (3, 'PRIYA', 3000); INSERT INTO emp_source VALUES (4, 'KAVIN', 4000); COMMIT; DROP TABLE emp_target; CREATE TABLE emp_target(empno NUMBER PRIMARY KEY, ename VARCHAR2(10), sal NUMBER(5));/*ename size is 10*/ INSERT INTO emp_target VALUES (1, 'RAVI', 1000); INSERT INTO emp_target VALUES (2, 'RAGHU', 2000); INSERT INTO emp_target VALUES (3, 'PRIYA', 3000); INSERT INTO emp_target VALUES (4, 'KAVIN', 4000); COMMIT; INSERT INTO emp_source VALUES(5, 'SUMAN CHANDRA', 5000); UPDATE emp_source SET sal = 3500 WHERE empno = 3; COMMIT; /*To sync emp_target table data with emp_source table we have to use one insert and one update. Rather a single MERGE statement resolves the purpose*/ UPDATE emp_target SET sal = (SELECT emp_source.sal FROM emp_source WHERE emp_source.empno = emp_target.empno); INSERT INTO emp_target (SELECT * FROM emp_source WHERE empno NOT IN (SELECT empno FROM emp_target)); /*Error report - ORA-12899: value too large for column "ORADB"."EMP_TARGET"."ENAME" (actual: 13, maximum: 10)*/ ROLLBACK; MERGE INTO emp_target USING emp_source ON (emp_target.empno = emp_source.empno) WHEN MATCHED THEN UPDATE SET emp_target.sal = emp_source.sal WHEN NOT MATCHED THEN INSERT VALUES(emp_source.empno, emp_source.ename, emp_source.sal); /*Error report - ORA-12899: value too large for column "ORADB"."EMP_TARGET"."ENAME" (actual: 13, maximum: 10)*/ /*Create dbms_errlog table*/ BEGIN dbms_errlog.create_error_log(dml_table_name => 'emp_target'); END; SELECT * FROM err$_emp_target; MERGE INTO emp_target USING emp_source ON (emp_target.empno = emp_source.empno) WHEN MATCHED THEN UPDATE SET emp_target.sal = emp_source.sal WHEN NOT MATCHED THEN INSERT VALUES(emp_source.empno, emp_source.ename, emp_source.sal) LOG ERRORS INTO err$_emp_target REJECT LIMIT UNLIMITED; SELECT * FROM emp_source; SELECT * FROM emp_target; SELECT * FROM err$_emp_target;
34. Difference between COUNT(*), COUNT(expr), COUNT(DISTINCT expr)
| COUNT(*) | COUNT(expr) | COUNT(DISTINCT expr) |
| This returns several rows in a table including the duplicate rows and the rows containing null values in the columns. | This returns the number of non-null values in the column identified by an expression. | This returns the number of unique, non-null values in the column identified by an expression. |
| SELECT COUNT(*) FROM emp; –14 | SELECT COUNT(comm) FROM emp; — 4 | SELECT COUNT(DISTINCT deptno) FROM emp; — 3 |
35. REF Cursor
Ref Cursor + Return Type = Strong Ref Cursor
Ref Cursor – Return Type = Weak Ref Cursor
| Strong Ref Cursor | Weak Ref Cursor | SYS_RefCursor |
| RefCursor with return type | RefCursor without return type | Variable declartion with datatype as SYS_REFCURSOR |
SET SERVEROUTPUT ON;
CLEAR SCREEN;
DECLARE
cur_var SYS_REFCURSOR;
emp_name emp.ename%TYPE;
emp_sal emp.sal%TYPE;
BEGIN
OPEN cur_var FOR SELECT ename, sal FROM emp WHERE empno = 7839;
FETCH cur_var INTO emp_name, emp_sal;
CLOSE cur_var;
DBMS_OUTPUT.PUT_LINE('Employee '||emp_name||' salary is '||emp_sal);
END;
|
||
36. SYS REF Cursor
SYS_RefCursor is a pre-defined weak ref cursor which comes built-in with the Oracle database software.
37. PRAGMA AUTONOMOUS_TRANSACTION
An autonomous transaction is an independent transaction started by another transaction, the main transaction. Autonomous transaction do SQL operations and commit or rollback, without committing or rolling back the main transaction.
A commit or rollback is mandatory in autonomous transaction. In case a particular transaction to be commit or rollback then we use this. A child transaction can be committed irrespective of parent transaction.
CLEAR SCREEN;
SET SERVEROUTPUT ON;
DROP TABLE autonomous_transaction;
CREATE TABLE autonomous_transaction
(ln_number NUMBER);
CREATE OR REPLACE PROCEDURE autonomous_transaction_proc (
p_number NUMBER
) IS
PRAGMA autonomous_transaction;
BEGIN
INSERT INTO autonomous_transaction VALUES ( p_number );
COMMIT;
END;
BEGIN
INSERT INTO autonomous_transaction VALUES ( 1 );
AUTONOMOUS_TRANSACTION_PROC(2);
INSERT INTO autonomous_transaction VALUES ( 3 );
ROLLBACK;
END;
SELECT * FROM autonomous_transaction;
/*2*/
38. Difference between 11i and R12
| 11i | R12 |
| Adapts MOA (Multi Organization Architecture) | Adapts MOAC (Multi Org Access Control) concept |
| Each responsibility is assigned to one OU | Each responsibility can be assigned to multiple OU’s. Means we can access multiple operating units from single responsibility. |
| To get access into one OU from single responsibility we will use ‘MO: Operating Unit’ profile option | To get access into multiple OU’s from single responsibility we will use ‘MO: Security Profile’ profile option |
| Forms based | Forms and OAF based |
| 11.5.0; 11.5.1; 11.5.2; ….11.5.9 | 12.0.1; 12.1.1; 12.1.2; 12.1.3…12.2.10(latest) |
| Added a new feature SLA (Sub Ledger Accounting) |
39. Difference between R12.1.3 and R12.2
Latest version is 12.2.10 and stable is 12.2.9
Premier Support for E-Business Suite Release 12.1 is available till December 2021. Whereas Premier Support for Oracle E-Business Suite 12.2 extended through at least 2031.
1)In R12.2 we have dual filesystems fs1(run filesystem) and fs2(patch filesystem), where as In R12.1.3 we only one application filesystem.
2)In R12.2 we have the Application servers replaced by Weblogic server to manage the technology statck.
3)In 12.1.3 we have adpatch utility for patching, In R12.2.4 we have adop(online patching) utility patching.
adop utility involves 5 phases to apply a standard patch in Oracle EBS R12.2.4.
Prepare >> Apply >> Finalize >> Cutover >> Cleanup
adop online patching utility doesn’t require downtime. It involves minimal downtime during cutover phase where switching of filesystems happens where as in adpatch we just apply patch most of the times by bringing down applications or in hot patch mode.
4) When we install Oracle E-Business Suite R12.1 we get an 11g database by default. But in Oracle E-Business Suite R12.2 we get a 12c database by default.
40. TCA
TCA in 11i
11i TCA already equipped to handle the following entities
–>Customer
–>Employee
–>Student
TCA in R12 Includes:
New trading entities
–>Suppliers
–>Banks & Bank Branches
–>Legal Entity