Oracle Performance & Tuning
Tuning concepts start from 23
1. dbms_profiler
2. Index
Statistics
SQL Tuning
Optimization Techniques
Explain Plan
Optimizer Hints
Different categories of Oracle Hints
1. dbms_profiler
Step 1 : DBMS_PROFILER package should exists
SELECT *
FROM dba_objects
WHERE object_name = 'DBMS_PROFILER'
AND object_type LIKE 'PACKAGE%';
Step 2: Check if below three tables exist or not. Else get the path of proftab.sql and execute as the below @ command and then check the tables.
@C:\app\gdsrikanth\virtual\product\12.2.0\dbhome_1\rdbms\admin\proftab.sql SELECT * FROM plsql_profiler_data; SELECT * FROM plsql_profiler_units; SELECT * FROM plsql_profiler_runs;
Step 3: Create three sample procedures as below:
CREATE OR REPLACE PROCEDURE proc_c AS
ln_avg_sal NUMBER;
BEGIN
FOR i IN 1..200 LOOP
SELECT AVG(sal) INTO
ln_avg_sal
FROM emp;
END LOOP;
END;
CREATE OR REPLACE PROCEDURE proc_b AS
ld_date DATE;
BEGIN
FOR i IN 1..200 LOOP
proc_c;
SELECT SYSDATE INTO
ld_date
FROM dual;
END LOOP;
END;
CREATE OR REPLACE PROCEDURE proc_a AS
ln_count NUMBER;
BEGIN
SELECT COUNT(*) INTO
ln_count
FROM user_tables
,all_objects;
FOR i IN 1..200 LOOP
proc_b;
END LOOP;
END;
EXEC dbms_profiler.start_profiler('performance_run'); -- 'performance_run' = any name
EXEC proc_a; -- Execution time 563.336 seconds
EXEC dbms_profiler.stop_profiler();
SELECT * FROM plsql_profiler_data;
SELECT * FROM plsql_profiler_units;
SELECT * FROM plsql_profiler_runs;
SELECT plsql_profiler_runs.run_date
,plsql_profiler_runs.run_comment
,plsql_profiler_units.unit_type
,plsql_profiler_units.unit_name
,plsql_profiler_data.line#
,plsql_profiler_data.total_occur
,plsql_profiler_data.total_time
,plsql_profiler_data.min_time
,plsql_profiler_data.max_time
,round(plsql_profiler_data.total_time / 1000000000) total_time_in_sec
,trunc( ( (plsql_profiler_data.total_time) / (SUM(plsql_profiler_data.total_time) OVER() ) ) * 100,2) percent_time_taken
FROM plsql_profiler_data
,plsql_profiler_runs
,plsql_profiler_units
WHERE 1 = 1
AND plsql_profiler_data.total_time > 0
AND plsql_profiler_data.runid = plsql_profiler_runs.runid
AND plsql_profiler_units.unit_number = plsql_profiler_data.unit_number
AND plsql_profiler_units.runid = plsql_profiler_runs.runid
ORDER BY plsql_profiler_data.total_time DESC;
From the above query look for unit_name, line#, total_occur, total_time, percent_time_taken and we can easily identify what needs to be tuned. Here its proc_c
| unit_name | line# | total_occur | total_time | min_time | max_time | total_time_in_sec | percent_time_taken |
| PROC_C | 7 | 8000000 | 335130258903 | 19999 | 54575816 | 335 | 98.01 |
| XML_SCHEMA_NAME_PRESENT | 17 | 3019 | 1900722624 | 258999 | 1738994 | 2 | 0.55 |
| XML_SCHEMA_NAME_PRESENT | 34 | 3016 | 1880505692 | 293999 | 1557994 | 2 | 0.540.37 |
| PROC_B | 8 | 40000 | 1270915737 | 13999 | 633997 | 1 | 0.35 |
| PROC_C | 5 | 8040000 | 1223313896 | 999 | 828997 | 1 |
Step 4: Delete data from tables in same sequence
TRUNCATE TABLE plsql_profiler_data; DELETE FROM plsql_profiler_units; DELETE FROM plsql_profiler_runs;
Step 5: Tune the query
CREATE OR REPLACE PROCEDURE proc_c AS
CURSOR c1 IS SELECT AVG(sal) a FROM emp;
TYPE emptype IS
TABLE OF c1%rowtype;
ln_avg_sal emptype := emptype ();
BEGIN
OPEN c1;
LOOP
FETCH c1 BULK COLLECT INTO ln_avg_sal;
EXIT WHEN ln_avg_sal.count = 0;
FOR i IN 1..200 LOOP
ln_avg_sal.extend;
dbms_output.put_line('ln_avg_sal : ' || ln_avg_sal(i).a);
END LOOP;
END LOOP;
END;
Execute the query in step 3 to see the difference.
2. Index
Index is a schema object that contains an entry for each value that appears in the indexed columns. Index sorts the records in ascending order on the column/s on which it was created so full table scan will be avoided. The indexed column along with rowid column will be stored in another data set for faster retrieval of data.
Types:
i) B-Tree
ii) Bit Map
iii) Function based
iv) Reverse key
Statistics
• DBA determines the level of statistic collection on the database by setting the value of the STATISTICS_LEVEL parameter.
• The STATISTICS_LEVEL parameter can be set with three different value:
i) BASIC
ii) TYPICAL
iii) ALL
Other parameters that are affected by SLP – V$STATISTICS_LEVEL
Whenever you want to study Performance and Optimization of Oracle process we have to operate always at STATISTICS level. These levels are defined by the DBA as per the need and necessity. We can alter the STATISTICS level by using ALTER SYSTEM statement and specifying the STATISTICS level.
SGA size – V$SGA or SHOW SGA
Free space in SGA – V$SGASTAT
Pool designates the pool of memory in which memory name resides.
i) shared pool : This is the memory allocated for shared pool.
ii) large pool: This is the memory allocated for large pool.
iii) java pool: This is the memory allocated to Java operations
iv) streams pool: This is the memory allocated for stream pool.
Occupied space in SGA – V$SGA_TARGET_ADVICE – SUM(SGA_SIZE)
bytes/1024 = kb
kb/1024 = mb
mb/1024 = gb
Memory size – V$MEMORY_TARGET_ADVICE
Current size of SGA dynamic free memory – V$SGA_DYNAMIC_FREE_MEMORY
SGA Target – SELECT ((SELECT SUM(value) FROM V$SGA)-(SELECT current_size FROM V$SGA_DYNAMIC_FREE_MEMORY)) SGA_TARGET FROM DUAL;
See settings for parameter:
SHOW PARAMETER statistics_level;
SHOW PARAMETER timed_statistics;
SHOW PARAMETER sga_target;
SHOW PARAMETER sga_max_size;
Wait events – V$EVENT_NAME
V$SESSION
V$SERVICES
V$SERVICE_EVENT
System level statistics – V$SYSSTAT
V$SQL
V$SQLAREA
SQL Tuning
What is SQL Tuning – SQL Tuning is the process of ensuring the SQL statements that are used or issued by an application will run and execute in the fastest possible time.
Issues to be taken into concern before SQL tuning is applied
1. The design of the database is applied strictly to the normalization or not, atleast 3rd normal form definitely and cross check for BCNF normal form.
2. Avoid number to character (TO_CHAR) conversion in the applications or SQL statements. Because number to character conversion will make the comparisons get applied with totally different state leading to performance degradation.
3. While implementing SELECT statement always design the logic to fetch only the required data from the DB server either in projection or in selection principle.
3.1. Avoid the usage of ‘*’ projection operator as this will scan the total metadata for confirmation of columns in the table.
3.2. Avoid selecting all the records from the table. Apply a WHERE clause at all stages at which it is required
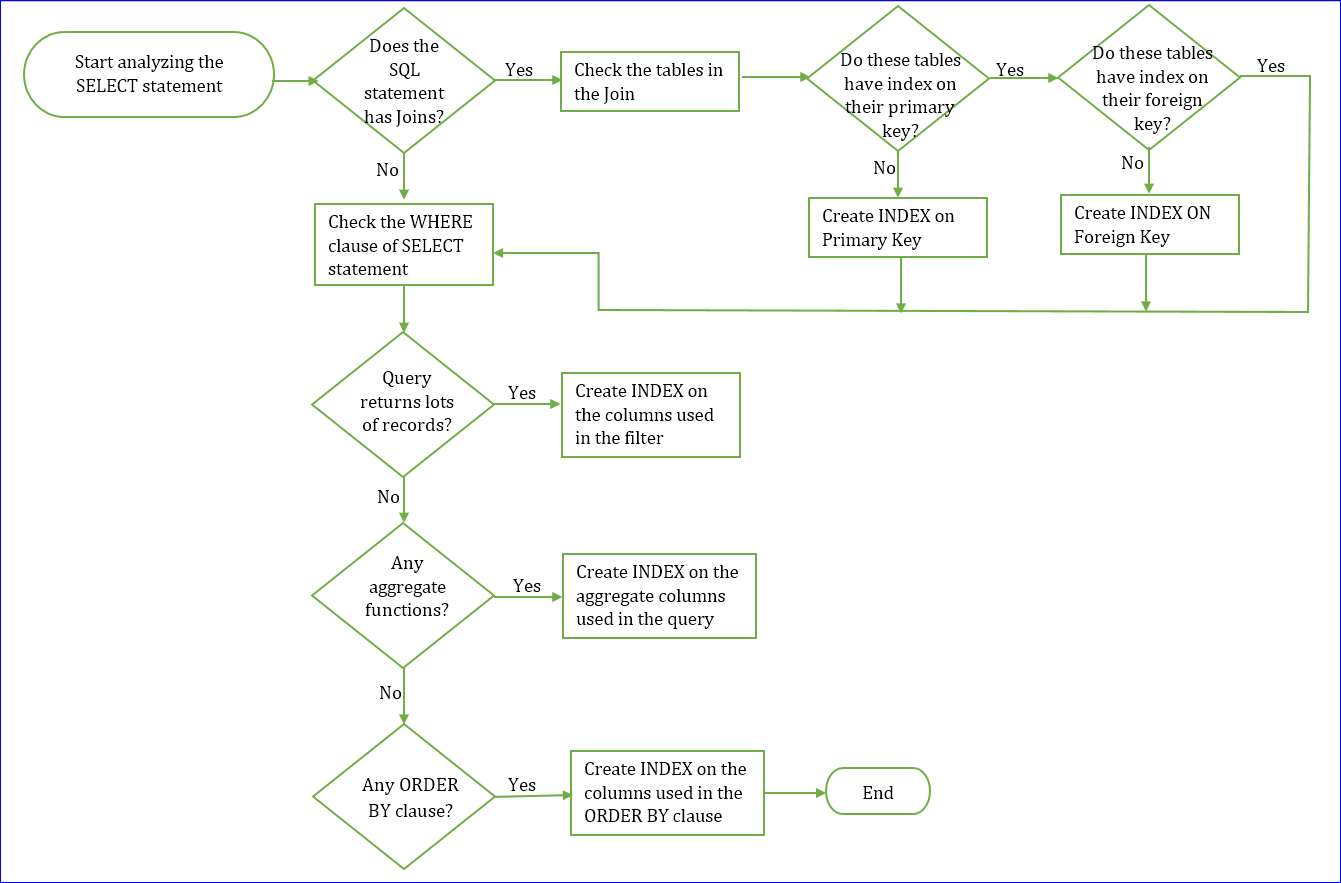
4. Create indexes with care at all stages for all the tables that are existing in the DB that definitely need indexes and can be used in the various SELECT statements.
4.1. Create indexes only for such tables that are mostly participating in the data search operations. The name of the columns of the table that are mostly used in the WHERE clause of the SELECT statement.
4.2. Avoid indexes on such table where the application has less number of search operations and the table is more used in
4.2.1. INSERT
4.2.2. UPDATE
4.2.3. DELETE
5. When writing SELECT statements maximum avoid full scans
5.1. Create proper index on proper column with proper combination of the columns.
5.2. Columns participating in the WHERE clause should be planned with proper suitable index
6. When using the comparison operators in the WHERE clause cross check proper operator is use with proper datatype value.
6.1. When using equality operator cross check for proper type with difference of NUMBERS, DATE and TIME
6.2. Make majority of the choices with principle of rejection rather than selection
6.3. Make a choice with careful analysis before using > and < operators as these operators can by pass the index usage
7. Be highly judgemental in using pattern matching operators like “LIKE” operator.
8. Maximum use the multi conditional logic applied with “AND” operator rather than “OR” operator. If in practicality “OR” operator is looking obvious to be used then prefer “IN” operator.
9. Tune the SQL queries always by examining the table structures before the “JOINS” and “SUB-QUERIES” are applied such that only the tables designed to the state of “JOINS” and “SUB-QUERIES” standards can give performance.
10. For queries that are executed on regular basis it is better to design procedures in the middle layer by using the concept of cursors and PL/SQL tables.
11. Optimize bulk data loading by dropping indexes on the tables on which the loading of the data is being done before the data loading is applied. Once the loading is completed re-create all the required indexes.
12. When executing transactions avoid usage of frequent “COMMIT” statements till fair amount of data changes are done and then execute one “COMMIT”.
13. Plan a clear strategy to defragment the DB on regular basis using the tools provided by DB.
Optimization Techniques
1. Use declared columns in the SELECT list rather than Projection operator ‘*’.
Incorrect: SELECT * FROM table_name;
Reason: The optimizer has to search the metadata to confirm the total number of actual columns along with the names. The metadata search increases the time and costs the performance.
Correct: SELECT column01, column02, … FROM table_name;
Reason: The optimizer is very clear with the column names that have to be actually included into this query which makes the query to increase the performance.
2. Usage of HAVING clause as a single row filter. If HAVING clause is existing in the query then make it confirmed to filter only GROUP functional data.
Incorrect:
SELECT column01, column02, ...
FROM tablename
GROUP BY column01, column02, ...
HAVING column01 = 'some_value';
SELECT ename, sal, deptno
FROM emp
GROUP BY ename, sal, deptno
HAVING deptno = 30;
SELECT column01, GROUP_FUNCTION(column_name)
FROM table_name
GROUP BY column01
HAVING column01 = 'value';
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno
HAVING deptno = 'value';Correct:
SELECT column01, column02, ...
FROM tablename
WHERE column01 = 'some_value';
SELECT ename, sal, deptno
FROM emp
WHERE deptno = 30;
SELECT column01, GROUP_FUNCTION(column_name)
FROM table_name
WHERE column01 = 'value'
GROUP BY column01;
SELECT deptno, SUM(sal)
FROM emp
WHERE deptno = 'value'
GROUP BY deptno;3. When too may sub queries are designed with duplication
i) Sub query is getting duplicated in the WHERE clause with the change of column names but the table name in the FROM clause is same in all the sub-queries.
Solution: Re-design the sub query from non-pair wise comparison to pair wise comparison(multi-column sub query or compound WHERE clause query).
Incorrect
SELECT column_name
FROM table_name01
WHERE column_name01 =
(
SELECT column_name01
FROM table_name02
WHERE column_name = value
)
AND
column_name02 =
(
SELECT column_name02
FROM table_name02
WHERE column_name = value
)Correct
SELECT column_name
FROM table_name01
WHERE (column_name01, column_name02) IN
(
SELECT column_name01, column_name02
FROM table_name02
WHERE column_name = value
)
ii) Sub query is getting duplicated in the FROM clause (IN-LINE views) for the same data or different data coming from columns.
Solution: Re-design sub query in in-line to a sub query with sub-factoring principle i.e WITH clause based sub-query
Incorrect
SELECT column_name
FROM
(
SELECT column_name01
FROM table_name02
WHERE column_name = value
)T1,
(
SELECT column_name02
FROM table_name02
WHERE column_name = value
)T2
WHERE T1.column_name01 = T2.column_name02;Correct
WITH
(
SELECT column_name01, column_name02
FROM table_name01
WHERE column_name = value
)T,
SELECT column_name
FROM T T1, T T2
WHERE T1.column_name01 = T2.column_name02;4) Generally queries that contain IN operator are slowest by performance. IN operator can give performance when it is part of the sub-query principle. Within the sub query where IN operator is being applied, cross analyze the sub-query to check whether the IN operator can be replaced by EXISTS operator then EXISTS operator is more better than IN operator.
Incorrect
SELECT column_name
FROM table_name
WHERE column_name IN (value01, value02, value03);Correct
SELECT column_name FROM table_name WHERE column_name IN ( SELECT column_name FROM table_name );SELECT column_name FROM table_name OT WHERE EXISTS ( SELECT 1 FROM table_name IT WHERE IT.column_name = OT.column_name );
5. In major cases certain JOIN operations can be converted to correlated sub queries then it is always better to apply the correlated sub query principle rather than working with JOIN principle. When working with certain JOIN principles we get duplicated pattern of data, in such cases if possible try to convert the JOIN principle to co-related sub query principle with EXISTS operator.
Incorrect
SELECT column_name01, column_name02
FROM table_name T1, table_name T2
WHERE T1.column_name = T2.column_name;
SELECT DISTINCT d.name, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno;Correct
SELECT column_name01, column_name02
FROM table_name T1
WHERE T1.column_name IN (SELECT column_name FROM table_name T2);
SELECT column_name01, column_name02 --Co-related sub query
FROM table_name T1
WHERE EXISTS (
SELECT 1
FROM table_name T2
WHERE T2.column_name = T1.column_name
);
SELECT DISTINCT d.name, d.loc
FROM dept d
WHERE EXISTS
(SELECT 1
FROM emp e
WHERE e.deptno = d.deptno);
6. When SET operators are implemented, rather than using UNION operator it is always performance oriented to use UNION ALL and then apply DISTINCT on the overall query to eliminate duplicates.
Incorrect
SELECT column_name01, column_name02
FROM table_name
WHERE column_name = value
UNION
SELECT column_name01, column_name02
FROM table_name
WHERE column_name = valueCorrect
SELECT DISTINCT column_name01, column_name02
FROM
(
SELECT column_name01, column_name02
FROM table_name
WHERE column_name = value
UNION ALL
SELECT column_name01, column_name02
FROM table_name
WHERE column_name = value
)7. Cross checking improper WHERE clause conditions.
Cross Check 01:
Incorrect
SELECT column_name
FROM table_name
WHERE column_name > value;
SELECT empno, ename, sal, comm
FROM emp
WHERE deptno > 10Correct
SELECT column_name
FROM table_name
WHERE column_name != value;
SELECT empno, ename, sal, comm
FROM emp
WHERE deptno != 10; --This is possible only if we are comparing with lowest or highest valueCross check 02:
Incorrect
SELECT column_name
FROM table_name
WHERE SUBSTR(column_name, 1, 3) = value;
SELECT ename, job
FROM emp
WHERE SUBSTR(Job, 1, 3) = 'MAN';Correct
SELECT column_name
FROM table_name
WHERE column_name LIKE 'Pattern%';
SELECT ename, job
FROM emp
WHERE Job LIKE 'MAN%';Cross Check 03:
Incorrect
SELECT column_name
FROM table_name
WHERE column_name = NVL(column_name, value);Correct
SELECT column_name
FROM table_name
WHERE column_name = NVL(:column_name, value);Note: Instead of using the value or column_name for comparison directly, its better to use bind variables which keeps the query in the shared pool for long time.
Cross Check 04:
Incorrect
SELECT column_name
FROM table_name
WHERE column_name >= value AND column_name <= value;Correct
SELECT column_name
FROM table_name
WHERE column_name BETWEEN value AND value;Cross Check 05:
Incorrect
SELECT column_name
FROM table_name
WHERE column_name || column_name = 'value01 value02';
SELECT ename, deptno, job, sal
FROM emp
WHERE job || deptno = 'MANAGER30';Correct
SELECT column_name
FROM table_name
WHERE column_name = value01 AND column_name = value02;
SELECT ename, deptno, job, sal
FROM emp
WHERE job = 'MANAGER' AND deptno = 30;Cross Check 06:
Incorrect
SELECT column_name
FROM table_name
WHERE column_name + value < value;
SELECT ename, sal, deptno
FROM emp
WHERE sal + 100 < 2500;Correct
SELECT column_name
FROM table_name
WHERE column_name < value; --Where the value is calculated by mathematical principle to look like a constanr finally that can suite for filter
SELECT ename, sal, deptno
FROM emp
WHERE sal < 2400;Cross Check 07:
Incorrect
SELECT column_name
FROM table_name
WHERE column_name NOT = value;Correct
SELECT column_name
FROM table_name
WHERE column_name > value;Cross Check 08: Wherever it is possible apply DECODE instead of using individual comparison logic because:
i) DECODE doesn’t scans the total columns when operating.
ii) Using DECODE we can avoid certain JOIN queries.
iii) As DECODE works on a column, it pulls the data for comparison without scanning the table multiple times.
iv) In certain cases the data that is being identified in classification by GROUP BY clause, is almost constant and very less manage then prefer DECODE than GROUP BY clause.
v) In certain cases when we expect the data to be sorted by a specific column using ORDER BY clause it may be preferable to use DECODE on that column.
Cross Check 09:
When dealing with very large binary objects like videos, audios and images, do not make them part of the actual DB table. Instead place these objects in a separate file system and store the path to that location.
Cross Check 10:
When writing SQL queries to implement and execute efficient performance always follow the general rules with which the optimizer works.
i) Declare all the SQL statements with SQL keywords and clauses in a single case.
ii) Always write SQL statements in multiple lines, generally with every clause on a single new line.
iii) When writing the SQL statements it is always better to give one space with every word that is part of the SQL statement.
iv) When writing the SQL statements please follow the right or left alignment for every clause that is typed on a new line.
Generally the optimizers will either follow rule based optimization or cost based optimization. Even though the optimizer internally follows, definitely certain rules will make the optimizer to operate by following the generic rules that makes the parsing better and keep the SQL statements in the shared pool for long time.
40% of SQL tuning can be done by adjusting bad SQL into good SQL by following SQL tuning guide lines. Even after the adjustments are done if we do not acheieve the expected performance then we should go with alternate tuning standards like system level or resource level tuning.
1. What is meant by constant propagation in SQL tuning?
When multiple conditions are applied in WHERE clause using ‘AND’ operator or ‘OR’ operator, generally there can be a scenario that may work on the rule of transitivity, which can make the query get the same results without changing the logic of evaluation. A=B and B=C, directly we can write as A=C = Rule of Transitivity.Formal Method 01:
IF (A <comparisonoperator> B) IS TRUE AND (B <comparisonoperator> C) IS TRUE. Here we can directly use IF (A <comparisonoperator> C) IS TRUE
Here comparisonoperator could be <, >, =, !=
Formal Method 02:
IF constantvalue < columnname01 AND columnname01 = columnname02 AND NOT (columnname01 = constantvalue)
2. What is meant by dead code elimination in SQL tuning?
This concept is a scenario where the WHERE clause is applied with some conditions that are part of the WHERE clause but in execution it does not influences the logical evaluation.Formal Method:
IF column01 <comparisonoperator> column02 AND column02 <comparisonoperator> constantvalue
SELECT empno, ename, sal, job, deptno
FROM emp
WHERE deptno = 30 AND job = ‘SALESMAN’;–Here deptno = 30 is dead code since we have SALESMAN only in dept 30.
3. What is meant by constant folding in SQL tuning?
x – 10 = 50; Here x=60
This concept is a scenario where the WHERE clause is applied with a condition that is comparing a value after executing a mathematical expression by directly putting a constant in calculation.
Formal Method:
IF columnname + somevalue = value then we can write this as columnname = value. Value is calculated from the constant folding logic as value-somevalue.
4. Transforming UNION logic to a DISTINCT with OR operator
Incorrect
SELECT *
FROM tablename
WHERE column1 = 5
UNION
SELECT *
FROM tablname
WHERE column2 = 5
SELECT job
FROM emp
WHERE deptno = 10
UNION
SELECT job
FROM emp
WHERE deptno = 30;Correct
SELECT DISTINCT *
FROM tablename
WHERE column1 = 5 OR column2 = 5;
SELECT DISTINCT job
FROM emp
WHERE deptno IN (10, 30);5. Transforming MINUS logic to a relational logic
Incorrect
SELECT *
FROM tablename
WHERE columnname = 7
MINUS
SELECT *
FROM tablename
WHERE columnname = 8Correct
SELECT *
FROM tablename
WHERE columnname = 7 AND NOT columnname = 8;6. Multi conditional WHERE clause to CASE conversion
Cost based optimizers work only in Oracle but majority of DB’s are Rule based.
Incorrect
SELECT *
FROM tablename
WHERE slow_function(columnname) = 25 OR slow_function(columnname) = 50;
SELECT *
FROM tablename
WHERE slow_function(columnname) IN (25, 50);Correct
SELECT *
FROM tablename
WHERE 1=
CASE slow_function(columnname)
WHEN 25 THEN 1
WHEN 50 THEN 1
END;7. Understanding general sorts
There are three variables that affect the speed of sorting in SQL statement execution. In the order of importance they are:
i) The number of rows that are being selected by the query
ii) The number of columns that are declared in the ORDER BY clause
iii) The defined length of the columns that are declared in the ORDER BY clause.
8. Points to concentrate when ORDER BY clause is part of the SELECT statement
i) An increase in the row count while querying the data has a geometric effect on the sort speed.
ii) Take any drastic step while writing the query to avoid the rows to be sorted.
iii) Take any drastic step while writing the query to avoid the unnecessary columns to be part of the order by clause.
iv) Maximum try to keep those columns in the ORDER BY clause whose length is minimum to the data size.
v) The fastest sort is always the Ascending order sort, with a pre-sorted set of integer values with uniqueness.
vi) Partial and duplicated values in the columns will slow the sorting process killing the performance.
vii) Any column that is storing the data in pre-sorted form increases the performance.
viii) Finally the defined length of the column in size really matters for sorting speed.
9. GROUP BY clause in the SELECT statement can affect the performance
i) GROUP BY clause in the SELECT statement will internally involves a SORT process on the data that is being groupped. Hence much of the rules that are applicable to the ORDER BY clause also get applied to GROUP BY clause.
ii) GROUP BY clause performs better when the number of columns to be groupped are less and the columns are small by their nature.
iii) Maximum avoid groupping of redundant columns(that is do not apply grouping with SET operators)
iv) When the grouping operation is done using joined tables, maximum reduce the data before expanding for grouping.
v) When grouping the joined tables the GROUP BY clause should contain the columns from the same table on which we are applying the GROUP functions.
10. When implementing the GROUP function in the SELECT statement
i) As major number of group functions will use the index that is created upon the column that is used in the group function it is better to create an index on the columns that are made to be part of the GROUP functions.
11. When Joins are part of the SELECT statement
Join plan of strategies:
When the join is being executed the strategy of the optimizer depends on
i) INDEXES
ii) Table size
iii) Selectivity
Joins generally execute as:
i) Hash Joins
ii) Nested loop joins – This give better performance when compared with Hash joins.
Explain Plan
An utility provided by Oracle to know the execution plan.
Information available in plan:
| Join method | Access method | Data operations like filter, sort or usage of some aggregations |
| Nested loop join — WHERE table1.column = table2.column Each record of table1 searches for record in table2 |
Full Table Scan (FTS) | |
| Hash join | Table access by ROWID | |
| Sort merge join — First sort all records and then merge (merge is similar to nested loop join) | Index unique scan | |
| Index range scan | ||
| Index skip scan | ||
| Full index scan | ||
| Fast full index scan | ||
| Index joins | ||
| Hash access | ||
| Cluster access | ||
| Bit map index |
EXPLAIN PLAN FOR SELECT * FROM per_all_people_f;
SELECT * FROM table(dbms_xplan.display);
–The below query also retrives same result as above
SELECT * FROM plan_table ORDER BY timestamp DESC;
Plan hash value: 2301238421
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 11M| 3656M| 168K (1)| 00:33:41 |
| 1 | TABLE ACCESS FULL| PER_ALL_PEOPLE_F | 11M| 3656M| 168K (1)| 00:33:41 |
--------------------------------------------------------------------------------------EXPLAIN PLAN FOR SELECT * FROM per_all_people_f papf WHERE papf.person_id = 1 AND SYSDATE BETWEEN papf.effective_start_date AND papf.effective_end_date;
SELECT * FROM table(dbms_xplan.display);
Plan hash value: 3559217434
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 1011 | 6 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| PER_ALL_PEOPLE_F | 3 | 1011 | 6 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | PER_PEOPLE_F_PK | 3 | | 3 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("PAPF"."PERSON_ID"=1 AND "PAPF"."EFFECTIVE_END_DATE">=SYSDATE@! AND
"PAPF"."EFFECTIVE_START_DATE"<=SYSDATE@!)
filter("PAPF"."EFFECTIVE_END_DATE">=SYSDATE@!)EXPLAIN PLAN FOR SELECT * FROM per_all_people_f papf, per_all_assignments_f paaf WHERE papf.person_id = paaf.person_id
AND papf.person_id = 1
AND papf.current_employee_flag = ‘Y’
AND SYSDATE BETWEEN papf.effective_start_date AND papf.effective_end_date
AND SYSDATE BETWEEN paaf.effective_start_date AND paaf.effective_end_date;
SELECT * FROM table(dbms_xplan.display);
Plan hash value: 1699109018
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 1132 | 14 (0)| 00:00:01 |
| 1 | MERGE JOIN CARTESIAN | | 2 | 1132 | 14 (0)| 00:00:01 |
|* 2 | TABLE ACCESS BY INDEX ROWID | PER_ALL_PEOPLE_F | 1 | 337 | 6 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | PER_PEOPLE_F_PK | 3 | | 3 (0)| 00:00:01 |
| 4 | BUFFER SORT | | 6 | 1374 | 8 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| PER_ALL_ASSIGNMENTS_F | 6 | 1374 | 8 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | PER_ASSIGNMENTS_F_N12 | 6 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("PAPF"."CURRENT_EMPLOYEE_FLAG"='Y')
3 - access("PAPF"."PERSON_ID"=1 AND "PAPF"."EFFECTIVE_END_DATE">=SYSDATE@! AND
"PAPF"."EFFECTIVE_START_DATE"<=SYSDATE@!)
filter("PAPF"."EFFECTIVE_END_DATE">=SYSDATE@!)
6 - access("PAAF"."PERSON_ID"=1 AND "PAAF"."EFFECTIVE_END_DATE">=SYSDATE@! AND
"PAAF"."EFFECTIVE_START_DATE"<=SYSDATE@!)
filter("PAAF"."EFFECTIVE_END_DATE">=SYSDATE@!)General points when an SQL statement is executing in Oracle:
i) In cost based optimizers (CBO), when the SQL statements is passed to the server, the CBO used the DB statistics available in the dynamic performance views to create an execution plan.
ii) The execution plan generated in step 1, will be used to navigate through the data existing in the DB tables.
What is the job of the Tuning Engineer?
i) Once the problem is highlighted by the DBA w.r.t the query the tuning engineer should first generate the ‘EXPLAIN PLAN’ upon the given query.
ii) Cross compare the ‘PLAN’ with after execution plan given by DBA.
iii) Find the differences if any in the ‘PLAN’. If found then analyze on that step to tune the query as per the tuning standards.
Oracle’s EXPLAIN PLAN ‘PLAN_TABLE’
i) PLAN_TABLE will store the explain plan process data.
ii) The PLAN_TABLE is actually in the control of SYS. But by requirement the admin can keep the PLAN_TABLE in the
a) Local schema
b) Shared schema
iii) The PLAN_TABLE helps to visualize the execution plans
iv) The PLAN_TABLE is used almost by all the Oracle SQL tools to display the explain plan of the query.
Configuration of PLAN_TABLE in Oracle
i) Connect to the SYS user with SYSDBA privileges.
ii) At the SQL prompt run the ‘utlxplan.sql’ script.
a) CONN SYS AS SYSDBA
b) @C:\oracle\Oracle11g\product\11.2.0\client_1\RDBMS\ADMIN\utlxplan.sql;
c) GRANT ALL ON SYS.PLAN_TABLE TO PUBLIC;
d) CREATE PUBLIC SYNONYM PLAN_TABLE FOR SYS.PLAN_TABLE;
i) Before AUTOTRACE can be applied within the particular user we should have ‘PLUSTRACE’ role available to the actual users operating the AUTOTRACE.
ii) PLUSTRACE role has to be granted by DBA to the corresponding users.
iii) PLUSTRACE role is not available in database by installation. We have to configure PLUSTRACE by running the corresponding plustrace.sql script.
SELECT e.ename, e.job, e.deptno, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno;
SET AUTOTRACE ON
SELECT e.ename, e.job, e.deptno, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno;
SET AUTOTRACE TRACEONLY
SET AUTOTRACE ON and SET AUTOTRACE TRACEONLY - Both gives same results
SET AUTOTRACE ON EXPLAIN
SELECT e.ename, e.job, e.deptno, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno;
SET AUTOTRACE ON STATISTICS
SELECT e.ename, e.job, e.deptno, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno;Before query execution we want to see the plan
EXPLAIN PLAN FOR SELECT e.ename, e.job, e.sal, d.dname, d.loc FROM emp e, dept d WHERE e.deptno = d.deptno;-- @C:\oracle\Oracle11g\product\11.2.0\client_1\RDBMS\ADMIN\utlxpls.sql --The above script will read the plan.Copy the plan in notepad++ SET AUTOTRACE TRACEONLYSELECT e.ename, e.job, e.sal, d.dname, d.loc FROM emp e, dept d WHERE e.deptno = d.deptno;--Again copy the above executed query plan and compare with previous plan. We can ignore bytes sent/ received via SQL*Net to client (2 statements) + SQL*Net roundtrips to/from client. If we have more number of recursive calls in latest plan than previous, then we need to tune.
DBMS_XPLAN Package
i) This package is provided by Oracle and it is under the control of the SYS user.
ii) SYS user will share this package with all the other users by granting the relevant permissions by requirement.
iii) DBMS_XPLAN package helps in formatting the output of the explain plan.
iv) This package is actually a replacement of the ‘utlxpls.sql’ script.
The basic setup for DBMS_XPLAN package
i) Connect to SYS user as SYSDBA – CONN SYS AS SYSDBA
ii) Run the ‘utlsampl.sql’ script file – @C:\oracle\Oracle11g\product\11.2.0\client_1\RDBMS\ADMIN\utlsampl.sql
iii) Create the plan table if not existing
a) @C:\oracle\Oracle11g\product\11.2.0\client_1\RDBMS\ADMIN\utlxplan.sql
iv) Create a PUBLIC SYNONYM PLAN_TABLE FOR SYS.PLAN_TABLE, if not existing
v) GRANT ALL ON SYS.PLAN_TABLE TO PUBLIC;
Utilizing the services of DBMS_XPLAN package
i) Connect to any user in which we want to analyze the SQL statement.
ii) Write the EXPLAIN PLAN for the required SELECT statement without statement ID
EXPLAIN PLAN FOR
SELECT e.ename, e.job, e.sal, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno;iii) Display the explain plan for the previous SELECT statement by using
select * from table(dbms_xplan.display);DISPLAY function in DBMS_XPLAN package:
i) DISPLAY function will accept 3 optional parameters :
a) Table_Name : Name of the plan table to use. Default is ‘Plan_Table’
b) Statement_ID : The Statement ID for which the plan has to be displayed. If not mentioned takes the ID as NULL, which is the recent latest EXPLAIN PLAN that is generated.
c) Format: This controls the detail of the plan to be displayed where the default is ‘TYPICAL’. The other values for the format that can be used are: ‘BASIC’, ‘ALL’, ‘SERIAL’, ‘ADVANCED’.
iv) Write the EXPLAIN PLAN for the required SELECT statement with statement ID
EXPLAIN PLAN SET STATEMENT_ID = 'EMPDEPT02' FOR
SELECT e.ename, e.job, e.sal, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno AND e.deptno = 30;v) Display the explain plan for the previous SELECT statement by using statement ID and default statistics to ‘TYPICAL’
select * from table(dbms_xplan.display('PLAN_TABLE', 'EMPDEPT02')); --This is default statistics
select * from table(dbms_xplan.display('PLAN_TABLE', 'EMPDEPT02', 'BASIC')); -- Basic statistics
select * from table(dbms_xplan.display('PLAN_TABLE', 'EMPDEPT02', 'SERIAL')); --Serial statistics
select * from table(dbms_xplan.display('PLAN_TABLE', 'EMPDEPT02', 'ALL')); --All statistics
select * from table(dbms_xplan.display('PLAN_TABLE', 'EMPDEPT02', 'ADVANCED')); --Advanced statisticsDISPLAY_CURSOR function in DBMS_XPLAN package
1. DISPLAY_CURSOR function will get the plan statistics from the run time CACHE actually where the data is stored while executing the query rather than the PLAN_TABLE.
2. The Explain plan information is actually gathered from V$SQL_PLAN_STATISTICS_ALL, V$SQL and V$SQL_PLAN
3. Before using the DISPLAY_CURSOR function we should take permissions on the above three dynamic performance views.
4. DISPLAY_CURSOR function optionally accepts three parameters:
4.1. SQL_ID : This is the SQL_ID of the SQL statement that is existing in the CURSOR cache. This SQL_ID is available from the V$SQL, V$SQLAREA or V$SESSION in the column by name PREV_SQL_ID. If this parameter is omitted then it by default takes the recent previous SQL statement ID.
4.2. Child_Number : The Child_Number of the cursor as specified by the SQL_ID parameter. If the Child_Number is not provided then it will take SQL_ID by default.
4.3. Format : This parameter will define the statistics to be displayed by what depth in execution. ‘RUNSTATS_LAST’, ‘RUNSTATS_TOT’
SELECT e.empno, e.ename, e.job, d.deptno, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno
AND d.deptno = 30;
select * from table(dbms_xplan.display_cursor);
select * from table(dbms_xplan.display_cursor(format => 'ADVANCED'));show parameter cursor_sharing;
ALTER <SYSTEM/ SESSION> SET CURSOR_SHARING = SIMILAR;– SCOPE=MEMORY;
Collect STATISTICS for a particular table:
DBMS_STATS.GATHER_TABLE_STATS(‘user_name’, ‘table_name’, ESTIMATE_PERCENT => 100, METHOD_OPT => ‘for all columns size 1’);
ALTER SYSTEM SET DB_16K_CACHE_SIZE = 16M SCOPE = BOTH;
ANALYZE TABLE <table_name> COMPUTE STATISTICS;
SELECT * FROM all_tables; –more number of chain_cnt means more data is fragmented (fragment = different locations)
**Start from 39**
Optimizer Hints
Different categories of Oracle Hints
1. Hints for optimization approaches and goals
2. Hints for access paths
i. FULL
ii. CLUSTER
iii. HASH
iv. NO_INDEX
v. INDEX_ASC
vi. INDEX_DESC
vii. INDEX_COMBINE
viii. INDEX_JOIN
ix. INDEX_FFS
3. Hints for query transformation
4. Hints for join orders
5. Hints for join operations
i. USE_NL (NL = Nested Loop)
ii. NO_USE_NL
iii. USE_NL_WITH_INDEX
iv. USE_MERGE
v. NO_USE_MERGE
vi. USE_HASH
vii. NO_USE_HASH
6. Hints for parallel execution
7. Additional hints